While in search for further AQL query optimizations last week, we found that intermediate AQL
query results were copied one time too often in some cases. Precisely, the data that a query’s
ReturnNode will return to the caller was copied into the ReturnNode’s own register. With
ReturnNodes never modifying their input data, this demanded for something that is called
return-value optimization in compilers.
2.6 will now optimize away these copies in many cases, and this post shows which performance benefits can be expected due to the optimization.
The effect of the optimization can be demonstrated easily with a few simple AQL queries.
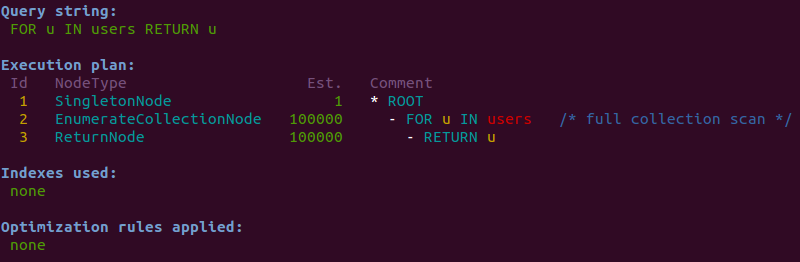
Let’s start with a query that simply returns all 100,000 documents from a collection users:
FOR u IN users RETURN u (the source data for the collection can be found here).
This query’s execution plan is already straight-forward and simple:
So where’s the problem?
The ReturnNode in this query (and other queries too) will copy its input data into its own output
register, only to finally hand the results to the query’s caller. This copying is most often unnecessary
as the ReturnNode will not modify its input. So the idea was to get rid of the copying action and
tell the query’s calling code in which (now different) register to look for the results.
Optimizing away the copying inside the ReturnNode made the query run faster already.
The same query now returns the 100,000 documents in 0.24 to 0.26 seconds, compared to 0.27 to 0.30 s
before applying the optimization.
Returning just an attribute of each document shows about the same improvement rates. The execution
times of the query FOR u IN users RETURN u._key drop to between 0.13 and 0.14 seconds with the
optimization, from initially between 0.15 and 0.17 seconds.
Another example query, FOR i IN 1..1000000 RETURN i, now runs in 0.58 to 0.61 seconds with
the optimization, compared to between 0.77 and 0.81 seconds without it.
These absolute figures may not look overly impressive, but they indicate relative improvements of between 10 and 25 %, which is quite nice. This is effectively saved CPU time that can now be used for something more productive.
Of course the performance improvements may not be that high for every imaginable AQL query.
Though the optimization may be active in most AQL queries, its effect will only be measurable
for queries that return a significant number of documents/values. Otherwise the share of the
ReturnNode’s work in the query’s overall computations may be too low to have any effect.
Additionally, the more work a query spends in performing other operations (e.g. filtering,
sorting, collecting), the less relevant will be the overall effect of the optimized ReturnNode.
Finally, when query results need to be shipped from the server to the client over a network,
the relative effect of the optimization may diminish further.
So your mileage may vary. But the optimization will not do any harm, and together with some other query optimizations already finished for 2.6 it will contribute to many AQL queries running faster than before.
AQL queries will benefit from the optimization automatically in ArangoDB 2.6, without requiring
any adjustments to the query string, the server configuration etc. The optimizer will automatically
apply the optimization for the main-level ReturnNode of every AQL query.
On a side note: the optimization will not be shown in the list of applied optimizer rules for the query. This is because the optimization is performed in some different place in the query executor, after applying the optimizer rules.