With the 2.8 beta phase coming to an end it’s time to shed some light on the improvements in the 2.8 AQL optimizer. This blog post summarizes a few of them, focusing on the query optimizer. There’ll be a follow-up post that will explain dedicated new AQL features soon.
Array indexes
2.8 allows creating hash and skiplist indexes on attributes which are arrays.
Creating such index works similar to creating a non-array index, with the
exception that the name of the array attribute needs to be followed by a [*]
in the index fields definition:
1 2 | |
Now if the tags attribute of a document in the posts collection is an array,
each array member will be inserted into the index:
1 2 3 | |
The index on tags[*] will now contain the values arangodb, database, aql and
nosql for the first document, arangodb, v8 and javascript for the second, and
javascript, v8 and nodejs for the third.
The following AQL will find any documents that have a value of javascript contained
in their tags value:
1 2 3 | |
This will use the array index on tags[*].
The array index works by inserting all members from an array into the index separately. Duplicates are removed automatically when populating the index.
An array index can also be created on a sub-attribute of array members. For
example, the following definition will make sure the name sub-attributes of
the tags array values will make it into the index:
1
| |
That will allow storing data as follows:
1 2 3 | |
The (index-based) selection query for this data structure then becomes
1 2 3 | |
Contrary to MongoDB, there is no automatic conversion to array values when inserting non-array values in ArangoDB. For example, the following plain strings will not be inserted into an array index, simply because the value of the index attribute is not an array:
1 2 3 | |
Note that in this case a non-array index can still be used.
Use of multiple indexes per collection
The query optimizer can now make use of multiple indexes if multiple filter conditions are combined with logical ORs, and all of them are covered by indexes of the same collection.
Provided there are separate indexes present on name and status, the
following query can make use of index scans in 2.8, as opposed to full
collection scans in 2.7:
1 2 3 | |
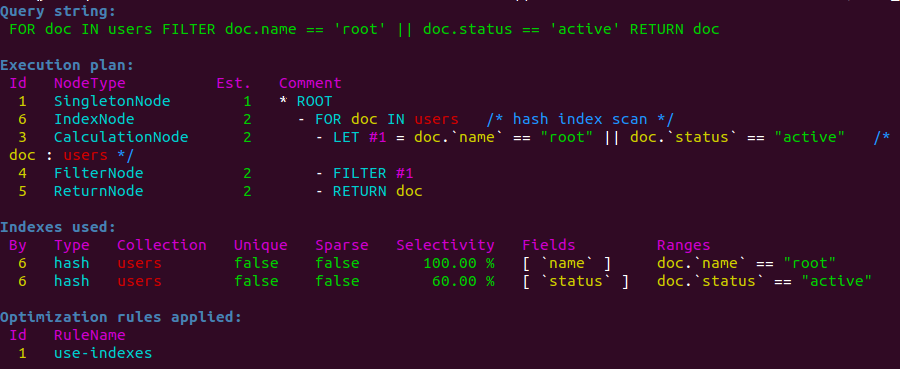
If multiple filter conditions match for the same document, the result will automatically be deduplicated, so each document is still returned at most once.
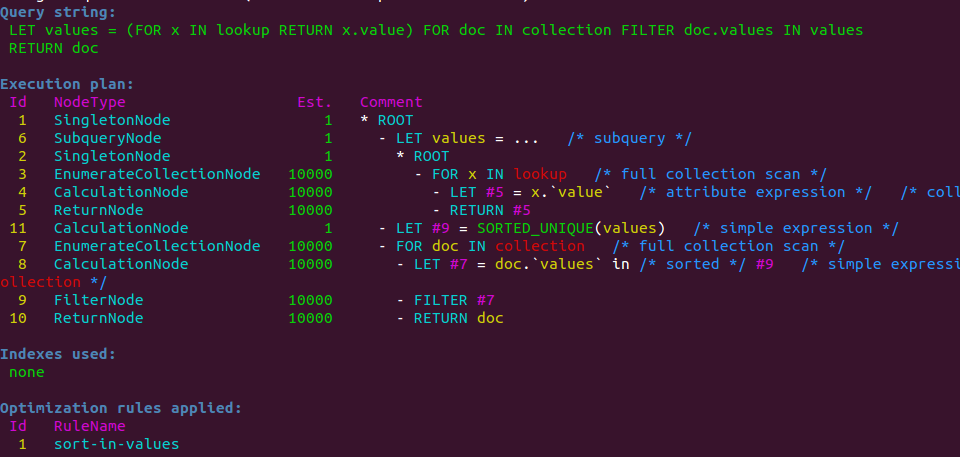
Sorted IN comparison
Another improvement for the optimizer is to pre-sort comparison values for IN and
NOT IN so these operators can use a (much faster) binary search instead of a linear search.
The optimization will be applied automatically for IN / NOT IN comparison values used
in filters, which are used inside of a FOR loop, and depend on runtime values. For example,
the optimization will be applied for the following query:
1 2 3 4 | |
The optimization will not be applied for IN comparison values that are value
literals and those that are used in index lookups. For these cases the comparison values
were already deduplicated and sorted.
“sort-in-values” will appear in the list of applied optimizer rules if the optimizer could apply the optimization:
Optimization for LENGTH(collection)
There are multiple ways for counting the total number of documents in a collection from
inside an AQL query. One obvious way is to use RETURN LENGTH(collection).
That variant however was inefficient as it fully materialized the documents before
counting them. In 2.8 calling LENGTH() for a collection will get automatically replaced
by a call to a special function that can efficiently determine the number of documents.
For larger collections, this can be several thousand times faster than the naive 2.7
solution.
C++ implementation for many AQL functions
Many existing AQL functions have been backed with a C++ implementation that removes
the need for some data conversion that would otherwise happen if the function were
implemented in V8/JavaScript only. More than 30+ functions have been changed, including
several that may produce bigger result sets (such as EDGES(), FULLTEXT(), WITHIN(),
NEAR()) and that will hugely benefit from this.
Improved skip performance
2.8 improves the performance of skipping over many documents in case no indexes and no filters are used. This might sound like an edge case, but it is quite common when the task is to fetch documents from a big collection in chunks and there is certainty that there will be no parallel modifications.
For example, the following query runs about 3 to 5 times faster in 2.8, and this
improvements can easily sum up to notable speedups if the query is called repeatedly
with increasing offset values for LIMIT:
1 2 3 | |