The upcoming ArangoDB version 2.8 (currently in devel) will provide a much better deadlock detection mechanism than its predecessors.
The new deadlock detection mechanism will kick in automatically when it detects operations that are mutually waiting for each other. In case it finds such deadlock, it will abort one of the operations so that the others can continue and overall progress can be made.
In previous versions of ArangoDB, deadlocks could make operations wait forever, requiring the server to be stopped and restarted.
How deadlocks can occur
Here’s a simple example for getting into a deadlock state:
Transaction A wants to write to collection c1 and to read from collection c2. In parallel, transaction B wants to write to collection c2 and read from collection c1. If the sequence of operations is interleaved as follows, then the two transactions prevent each other from making progress:
- transaction A successfully acquires write-lock on c1
- transaction B sucessfull acquires write-lock on c2
- transaction A tries to acquire read-lock on c2 (and must wait for B)
- transaction B tries to acquire read-lock on c1 (and must wait for A)
Here’s these such two transactions being started from two ArangoShell instances in parallel (left is A, right is B):
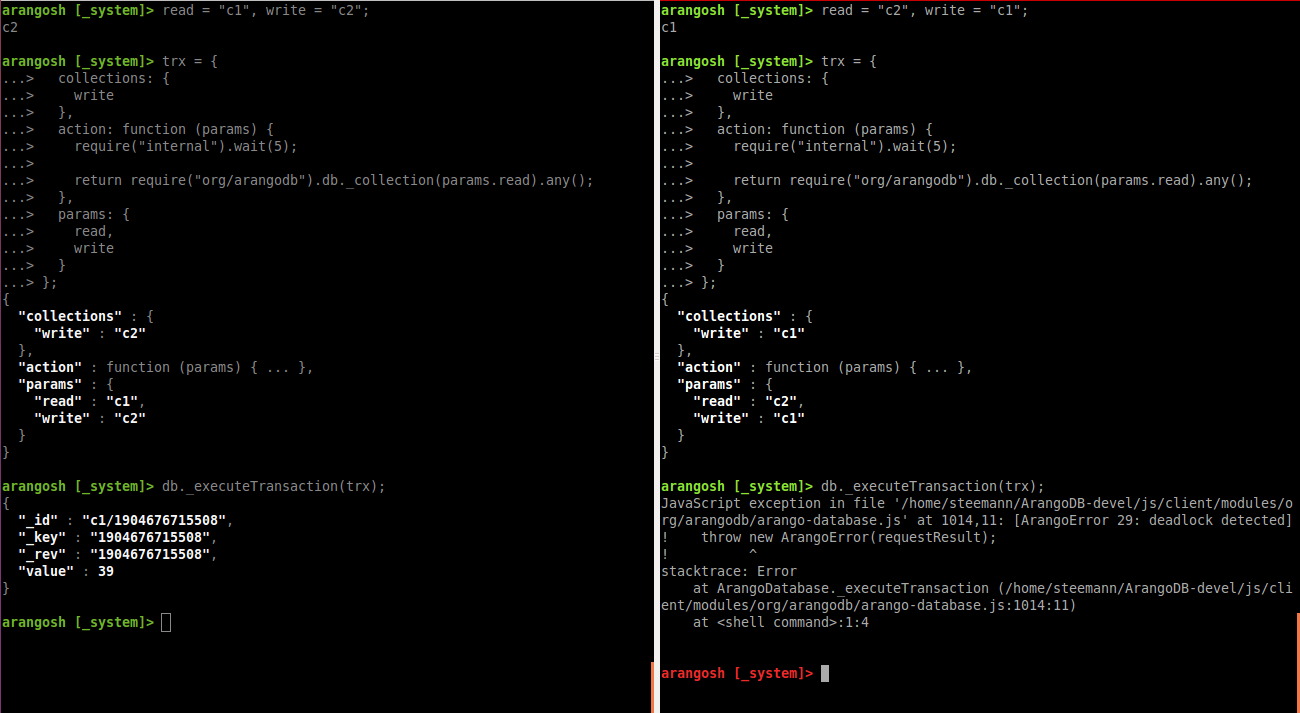
(note that this screenshot is from 2.8 and the automatic deadlock detection had already detected the deadlock and aborted one of the transactions)
In general, deadlocks can occur only when multiple operations (AQL queries or other transactions) try to access the same resources (collections) at the same time, and only if the operations already have already acquired some locks on these resources. And finally each operation needs to involve more than one collection, so there is the potential for already having acquired some locks but having to wait for others.
Dynamically added collections
Most operations will just work fine and will not cause any deadlocks. This is especially true for all operations that involve only a single collection. This leaves multi-collection AQL queries and multi-collection userland transactions.
Normally these will also work fine. This is because when a query or transaction starts, it will tell the transaction manager about the resources (collections) it will need. The transaction manager can then acquire the required resources in a deterministic fashion that prevents deadlocks. If all queries and transactions properly announce upfront which collections they will access, there will also be no deadlocks.
But for some operations its hard to predict at transaction start which collections will be accessed. This includes some AQL functions that can dynamically access collection data without having to specify the collection name anywhere in the query.
A good example for this is the GRAPH_EDGES AQL function, which will get
a graph name as its first input parameter, but not the names of the underlying
edge collection(s). When this function is used in an AQL query, the
query parser will just find a function parameter containing a graph name
but doesn’t know it’s a collection name.
1
| |
The "myEdges" graph name will look like any other string to the parser.
It does not know about the contexts in which strings may have special meanings.
Note that even if this would be fixed, the problem won’t go away entirely: a function call parameter in a query isn’t necessarily a constant but can be an arbitrary expression:
1 2 | |
At least in this case the AQL query parser won’t find a collection name,
so when the AQL query starts it is yet unknown which collections will be
accessed. Only at runtime when the function is actually executed, the
collection names will be looked up by finding the graph description in the
_graphssystem collection. Then the edge collections participating in
the graph will be added to the query dynamically. Only this dynamic addition
adds the potential for deadlock.
This dynamic addition of collections in unavoidable for conveniently querying data from collections whose names are unknown when the query starts.
Deadlock detection
Whenever transaction manager detects a deadlock in ArangoDB 2.8, it will automatically abort one of the blocking transactions. The transaction will be rolled back and all modifications it has made will be reverted. The operation will fail with error code 29 (deadlock detected) and raise an exception that the user can handle in the calling code.
Deadlocks will be found if two transactions mutually lock each other as seen in the screenshot above, but also for more complex setups. The following screenshot shows four parallel transactions that block each other indirectly.
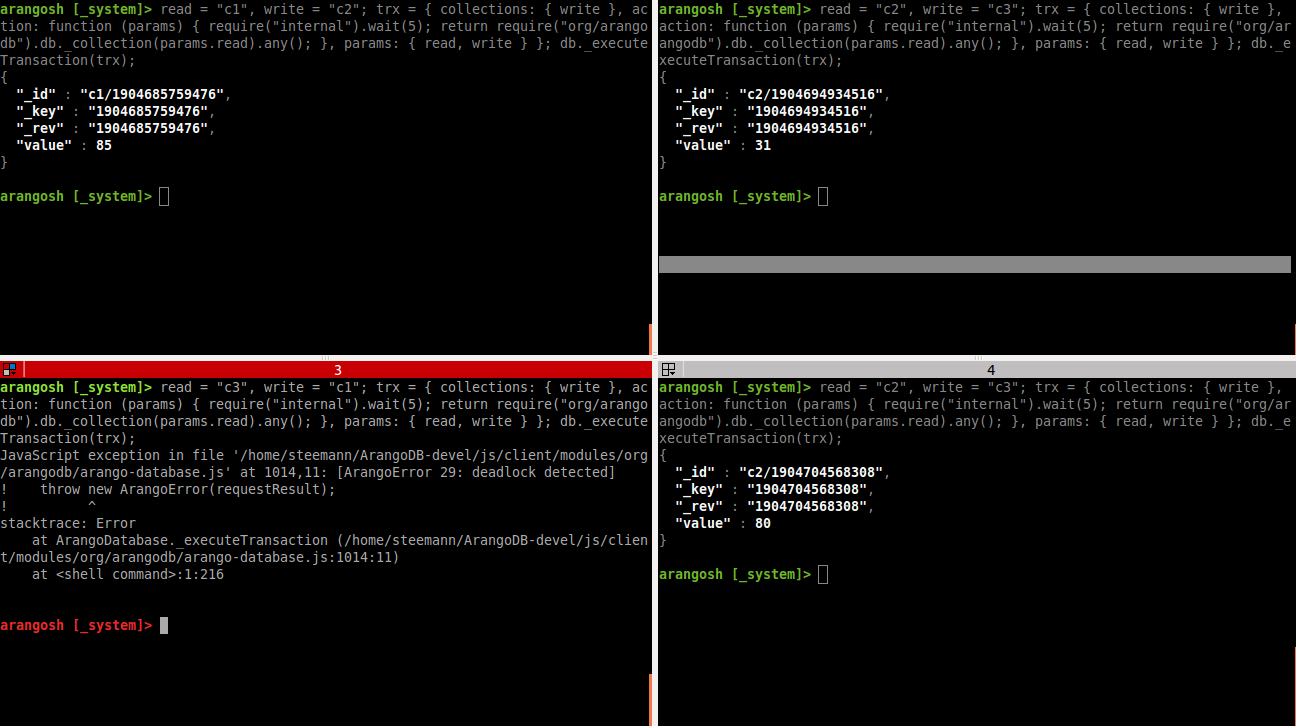
The top left window (transaction 1) will block the one in the top right (transaction 2), and is itself blocked by the transaction in the bottom left (transaction 3).
The transaction in the top right window (transaction 2) blocks the one in the bottom left (transaction 3), and is itself blocked by the one in the top left (transaction 1).
Transaction 3 (bottom left) is blocked by transaction 2 (top right). Transaction 4 (bottom right) does exactly the same as transaction 3.
With these transactions, we end up in this waiting state:
- T1 waits for T3 and T4
- T2 waits for T1
- T3 waits for T2
- T4 waits for T2
This waiting state is cyclic (T1 < T3 < T2 < T1) and therefore no progress can be made. This is exactly a situation in which the transaction manager will abort one of the transactions.
No configuration is required for the deadlock detection mechanism. It will always be active and cannot be configured or turned off.