ArangoDB 2.6 will feature an alternative hash implementation of the AQL COLLECT
operation. The new implementation can speed up some AQL queries that can not exploit indexes
on the COLLECT group criteria.
This blog post provides a preview of the feature and shows some nice performance improvements.
It also explains the COLLECT-related optimizer parts and how the optimizer will decide whether
to use the new or the traditional implementation.
Introduction to COLLECT
A quick recap: in AQL, the COLLECT operation can be used for grouping and optionally counting values.
Here’s an example, using flight data:
1 2 3 | |
This query will iterate over all documents in collection flights, and count the
number of flights per different _from value (origin airport). The query result will
contain only unique from values plus a counter for each:
1 2 3 4 5 6 7 8 9 | |
As the COLLECT will group its result according to the specified group criteria (flights._from
in the above query), it needs a way of figuring out to which group any input value does belong.
Before ArangoDB 2.6, there was a single method for determining the group. Starting with ArangoDB
2.6, the query optimizer can choose between two different COLLECT methods, the sorted method
and the hash method.
Sorted COLLECT method
The traditional method for determining the group values is the sorted method. It has been available in ArangoDB since the very start.
The sorted method of COLLECT requires its input to be sorted by the group criteria specified
in the COLLECT statement. Because there is no guarantee that the input data are already sorted
in the same way, the query optimizer will automatically insert a SORT statement into the query
in front of the COLLECT. In case there is a sorted index present on the group criteria attributes,
the optimizer may be able to optimize away the SORT again. If there is no sorted index present
on the group criteria attributes, the SORT will remain in the execution plan.
Here is the execution plan for the above query using the sorted method of COLLECT. We can see
the extra SortNode with id #7 being added by the optimizer in front of the COLLECT:
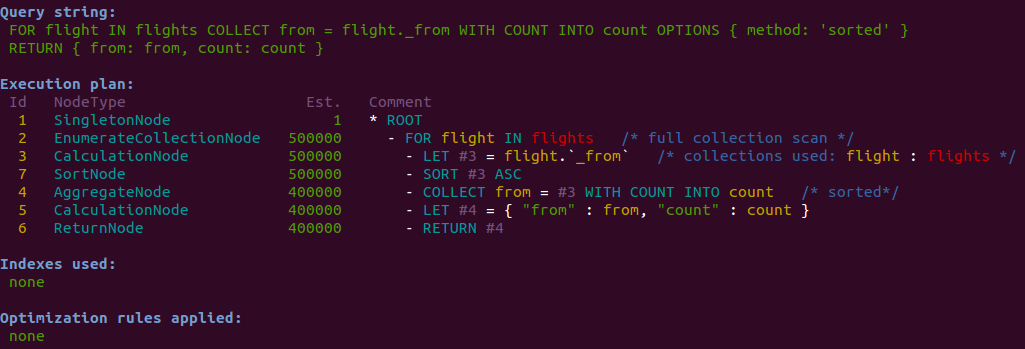
The sorted method of COLLECT is efficient because it can write out a group result whenever
an input value will start a new group. Therefore it does not need to keep the whole COLLECT
result in memory. The downside of using the sorted method is that it requires its input to be
sorted, and that this requires adding an extra SORT for not properly sorted input.
Hash COLLECT method
Since ArangoDB 2.6, the query optimizer can also employ the hash method for COLLECT. The
hash method works by assigning the input values of the COLLECT to slots in a hash table. It
does not require its input to be sorted. Because the entries in the hash table do not have a
particular order, the query optimizer will add a post-COLLECT SORT statement. With this extra
sort of the COLLECT result, the optimizer ensures that the output of the sorted COLLECT will
be the same as the output of the hash COLLECT.
Here is the execution plan for the above query when using the hash method of COLLECT.
Here we can see the extra SortNode with id #7 being added post-COLLECT:
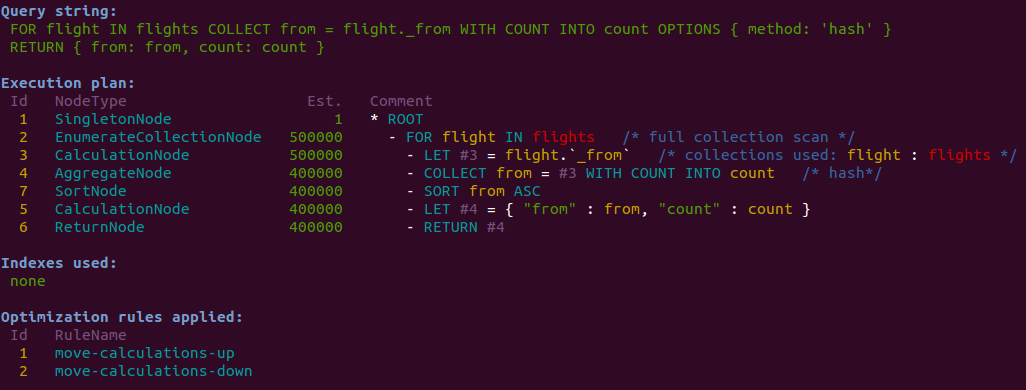
The hash method is beneficial because it does not require sorted input and thus no extra
SORT step in front. However, as the input is not sorted, it is never clear when a group is
actually finished. The hash method therefore needs to build the whole COLLECT result in memory
until the input is exhausted. Then it can safely write out all group results. Additionally,
the result of the hash COLLECT is unsorted. Therefore the optimizer will add a post-COLLECT
sort to ensure the result will be identical to a sorted COLLECT.
Which method will be used when?
The query optimizer will always take the initial query plan and specialize its COLLECT nodes to
using the sorted method. It will also add the pre-COLLECT SORT in the original plan.
In addition, for every COLLECT statement not using an INTO clause, the optimizer will create
a plan variant that uses the hash method. In that plan variant, the post-COLLECT SORT
will be added. Note that a WITH COUNT INTO is still ok here, but that using a regular INTO
clause will disable the usage of the hash method:
1 2 3 | |
If more than one COLLECT method can be used for a query, the created plans will be shipped through
the regular optimization pipeline. In the end, the optimizer will pick the plan with the lowest
estimated total cost as it will do for all other queries.
The hash variant does not require an up-front sort of the COLLECT input, and will thus be
preferred over the sorted method if the optimizer estimates many input elements for the COLLECT
and cannot use an index to process them in already sorted order. In this case, the optimizer
will estimate that post-sorting the result of the hash COLLECT will be more efficient than
pre-sorting the input for the sorted COLLECT.
The main assumption behind this estimation is that the result of any COLLECT statement will
contain at most as many elements as there are input elements to it. Therefore, the output of
a COLLECT is likely to be smaller (in terms of rows) than its input, making post-sorting more
efficient than pre-sorting.
If there is a sorted index on the COLLECT group criteria that the optimizer can exploit, the
optimizer will pick the sorted method because thanks to the index it can optimize away the
pre-COLLECT sort, leaving no sorts left in the final execution plan.
To override the optimizer decision, COLLECT statements now have an OPTIONS modifier. This
modifier can be used to force the optimizer to use the sorted variant:
1 2 3 | |
Note that specifying hash in method will not force the optimizer to use the hash method.
The reason is that the hash variant cannot be used for all queries (only COLLECT statements
without an INTO clause are eligible). If OPTIONS are omitted or any other method than sorted
is specified, the optimizer will ignore it and use its regular cost estimations.
Understanding execution plans
Which method is actually used in a query can found out by explaining it and looking at its execution plan.
A COLLECT is internally handled by an object called AggregateNode, so we have to look for that.
In the above screenshots, the AggregateNodes are tagged with either hash or sorted. This can
also be checked programatically by looking at the aggregationOptions.method attributes in the
JSON result of an explain().
Here is some example code to extract this information, limited to the AggregateNodes of the
query already:
1 2 3 4 5 6 7 8 9 10 | |
For the above query, this will produce something like this:
1 2 3 4 5 6 7 8 9 | |
Here we can see that the query is using the hash method.
Optimizing away post-COLLECT sorts
If a query uses the hash method for a COLLECT but the sort order of the COLLECT result
is irrelevant to the user, the user can provide a hint to the optimizer to remove the
post-COLLECT sort.
This can be achieved by simply appending a SORT null to the original COLLECT statement.
Here we can see that this removes the post-COLLECT sort:
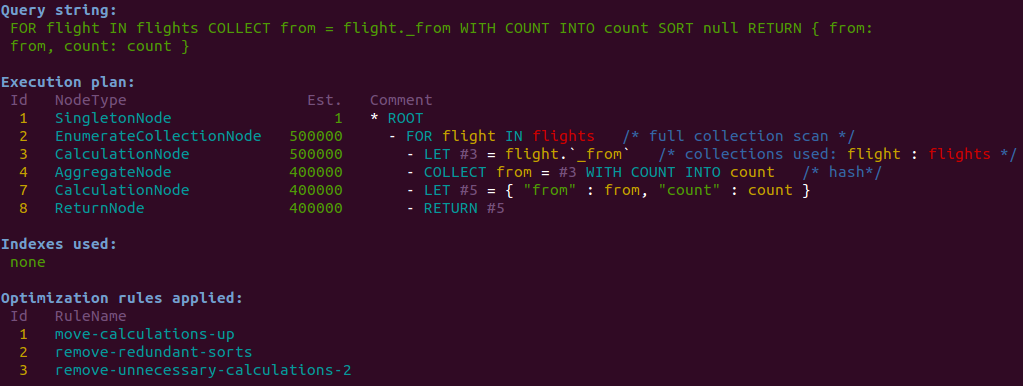
Performance improvements
The improvements achievable by using the hash method instead of the sorted method obviously depend on whether there are appropriate indexes present for the group criteria. If an index can be exploited, the sorted method may be just fine. However, there are cases when no indexes are present, for example, when running arbitrary ad-hoc queries or when indexes are too expensive (indexes need to be updated on insert/update/remove and also will use memory).
Following are a few comparisons of the sorted and the hash methods in case no indexes can be used.
Here’s the setup for the test data. This generates 1M documents with both unique and repeating string and numeric values. For the non-unique values, we’ll use 20 different categories:
1 2 3 4 5 6 7 8 9 | |
Now let’s run the following query on the data and measure its execution time:
1 2 3 | |
The worst case is when the COLLECT will produce as many output rows as there are input
rows. This will happen when using a unique attribute as the grouping criterion. We’ll run
tests on both numeric and string values.
Here are the execution times for unique inputs. It can be seen that the hash method
here will be beneficial if the post-COLLECT sort can be optimized away. As demonstrated
above, this can be achieved by adding an extra SORT null after the COLLECT statement.
If the post-COLLECT sort is not optimized away, it will make the hash method a bit more
expensive than the sorted method:
1 2 3 4 5 6 7 8 | |
Now let’s check the results when we group on an attribute that is non-unique. Following are the results for numeric and string attributes with 20 different categories each:
1 2 3 4 5 6 7 8 | |
In these cases, the result of the COLLECT will be much smaller than its input (we’ll
only get 20 result rows out instead of 1M). Therefore the post-COLLECT sort for the hash
method will not make any difference, but the pre-COLLECT sort for the sorted method
will still need to sort 1M input values. This is also the reason why the hash method
is significantly faster here.
As usual, your mileage may vary, so please run your own tests.